
How Inscribe uses generative AI to improve document classification and fraud detection (in any language)
Table of Contents
[ show ]- Loading table of contents...
Martina Pugliese, PhD
Correctly identifying a document's type is a key part of detecting fraud.
Each type (bank statement, payslip, utility bill, invoice, and more) carries different context and data, which influences which fraud checks are run.
At Inscribe, we’ve supported document classification for years, but recently we took a major leap forward. By incorporating generative AI into our pipeline, we significantly improved how many documents we classify – and how accurately we do it.
Improving on a strong foundation
Our original document classification system was built in-house using traditional machine learning. It learned to recognize patterns that distinguish, say, a bank statement from a utility bill. The system was accurate and robust, but it had growing limitations, especially as we expanded globally.
First, our training data was overwhelmingly in English, so performance dipped for non-English documents. That was a problem as our customers increasingly process international applications.
Second, while we supported an "UNKNOWN" type for unclassifiable or irrelevant documents (like selfies, pet photos, and vacation snapshots), we found that some documents that should have been classifiable weren’t being picked up, limiting our classification coverage.
Third, we lacked a streamlined way to add support for new document types. Expanding the system was possible, but slow and manual.
Enter generative AI
While we’ve continuously maintained and improved our ML system, major leaps required more than just tweaks. Generative AI gave us a way to accelerate meaningful improvements, without spending months curating new training datasets.
Our new hybrid pipeline combines the strengths of traditional ML, large language models (LLMs), and visual language models (VLMs):
- Non-English documents now bypass our original system entirely and are classified directly with an LLM, which understands the document content via text.
- English-language documents still use our original system – except when the result is UNKNOWN. In that case, we pass it through an LLM for a second opinion.
- All remaining unclassified documents, both English and non-English, go through a VLM. This model can analyze the visual content of documents, which is especially useful when the text alone is sparse or unhelpful.
VLMs are slower and more expensive, so we use them selectively, as a final step to reduce the UNKNOWN rate without impacting performance.
The impact
Since launching this improved pipeline on April 3, we’ve seen significant gains, especially for non-English documents. Their classification rate increased by 19%. English documents also improved. Given that some documents truly don’t fit any supported type, we’re confident we’re approaching the practical ceiling for classification.
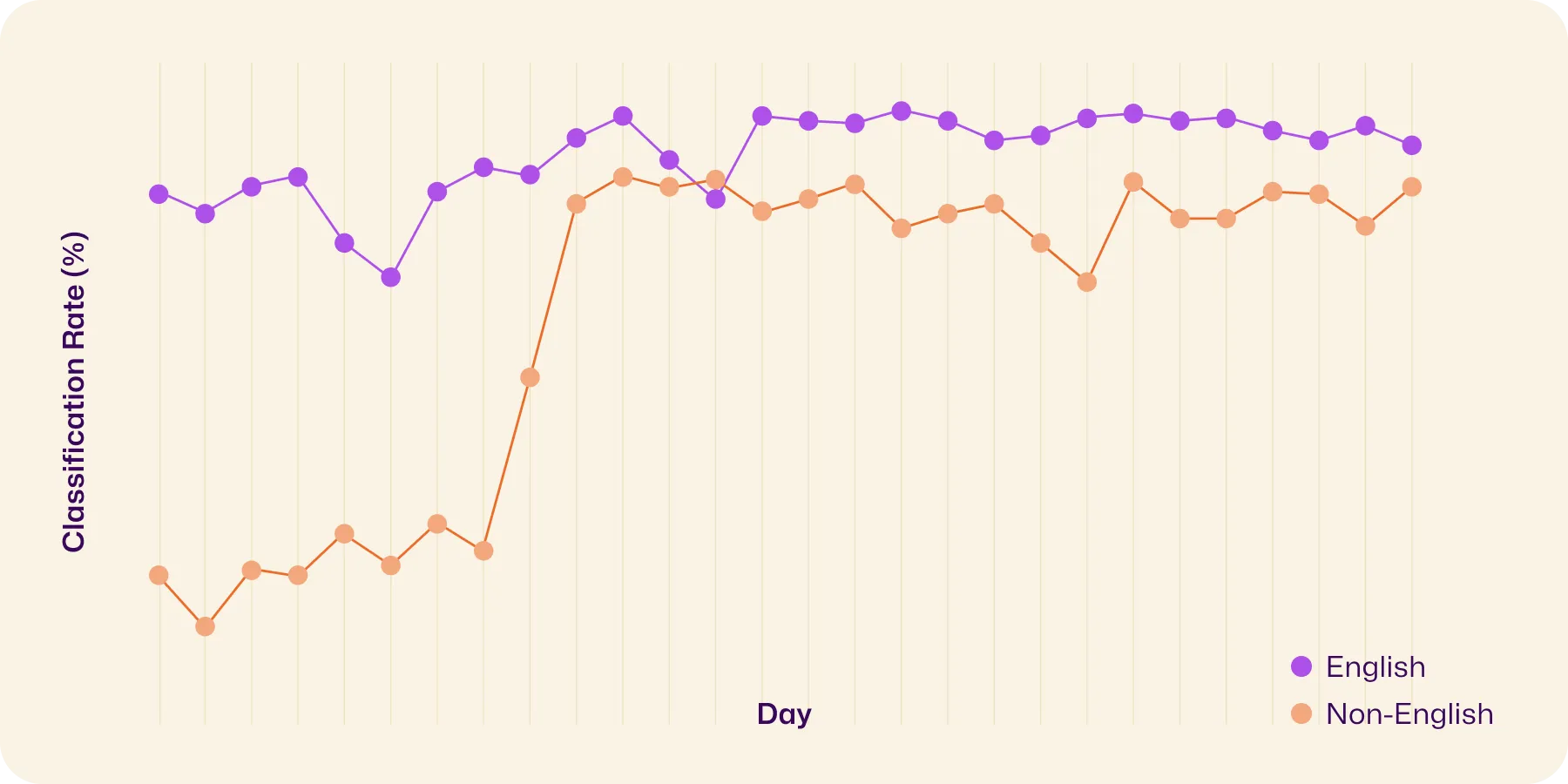
Even more exciting, this pipeline allows us to identify new document types we hadn’t previously supported. When an LLM returns something like “marriage certificate” or “medical record,” it gives us insight into what else users are uploading and helps us prioritize future expansions to our supported types.
Understanding what a document is lays the foundation for detecting what’s wrong with it. That’s why classification is so critical, and why we’re so excited about this progress. Generative AI isn’t just helping us detect fraud better; it’s helping us understand our data better. And that opens the door to smarter, faster, and more inclusive fraud detection going forward.
Want to learn more? Reach out to book a demo and speak with an AI expert from our team.
About the author
Martina Pugliese, PhD, is a Senior Research Scientist at Inscribe AI, where she applies her expertise in computer vision, artificial intelligence, and software engineering to solve complex problems. Martina is an experienced data scientist with a strong foundation in physics research, specializing in data analysis, statistical modeling, and machine learning. She is also deeply involved in the tech community, mentoring data professionals, creating data visualizations, and organizing events. Driven by curiosity and a passion for learning, she is committed to knowledge sharing and continuous growth.
What will our AI Agents find in your documents?
Start your free trial to catch more fraud, faster.